Typical Pictographs

Until recently, it was believed that the earliest examples of Chinese characters were those found in oracle bones used in divination rites dating back to the eighteenth century B.C. However, excavations made in China in 1986 have shown that at that time the Chinese characters had already had a history of 1200 years, which means that the Chinese script first appeared almost 5000 years ago.
The earliest characters were simple pictures of the things they represented.
Although all the principal writing systems of the world began with pictures,
these were in almost all cases simplified to abstract symbols that were eventually
used for their sound values, giving rise to the major alphabet systems of the
world. This happened everywhere but in China, where the primary function of
the characters has always been to express both meaning and sound, rather than
just sound.
|
The table shows examples of early character forms and their modern counterparts. The earliest characters were pictographs, which were simple pictures of things. Pictographs may be combined to form new characters, especially characters that express complex or abstract ideas. Thus 木 'tree' is combined with 木 to give 林 'woods' while three trees give 森 'forest'; a line added to the bottom of a tree gives 本, which means 'root' or 'origin'; and so on.
The shapes of the characters underwent a great deal of change over the several thousand years of their history. Many calligraphic styles, character forms, and typeface styles have evolved over the years; furthermore, the character forms were simplified as a result of various language reforms in China and Japan. The chart below shows various forms and styles for the characters 楽 and 女.
 |
Traditionally, Chinese characters are classified into six categories known as 六書 rikusho. Introduced some 1900 years ago in the Chinese classic dictionary 説文解字 setsumon kaiji, these have played a central role in Chinese lexicography. The first four categories are based on the character formation process; the last two are based on usage.
1. Pictographs (象形文字 shōkei moji) are simple hieroglyphs that are rough sketches of the things they represent. Example: modern 目 moku 'eye'.
2. Simple Ideographs (指事文字 shiji moji) suggest the meanings of abstract ideas, such as numerals and directions. Example: 三 san 'three'.
3. Compound Ideographs (会意文字 kaii moji) consist of two or more elements each of which contributes to the meaning of the whole. Example: 休 kyū 'rest' (person 人 resting under a tree 木).
4. Phonetic-Ideographic Characters (形声文字 keisei moji) consist of one element that roughly expresses meaning (usually called the radical), and another element that represents sound and often also meaning. Example: 茎 kei 'stem, stalk' consists of 'plants' and 圣 kei 'straight', i.e., the straight part of a plant.
5. Derivative Characters (転注文字 tenchū moji) are characters used in an extended, derived, or figurative sense. Example: 令 rei changed from its original meaning `command, order' to 'person who gives orders' to 'adminster, governor'.
6. Phonetic Loans Phonetic Loans (仮借文字 kasha moji) are characters borrowed to represent words phonetically without direct relation to their original meanings, or to characters used erroneously. Example: 豆 tō originally referred to an ancient sacrificial vessel, but is now used in the borrowed sense of 'bean'.
The great majority of characters are phonetic-ideographic (type 4 above). 民, for example, originally a picture of an eye pierced by a needle, represented a slave blinded by his master to keep him from escaping, but later changed to 'ignorant masses' or 'people' in general. As a phonetic-ideographic element in the formation of other characters, it represents the sound min and has a basic meaning of 'sightlessness' or 'darkness'. For example, 民 (abbreviated to 氏) is combined with 日 'sun' to give 昏 'darkness, dusk'; 眠 'sleep' consists of an eye (目) in a state of sightlessness (民). An interesting example is 婚 'marriage', which consists of 女 'woman' + 昏 'darkness'. According to one theory, this is because wedding ceremonies were held at night.1 In this way, a basic unit like 民 contributes its shape, its reading, and its meaning to the formation of other characters.
The table below shows several groups of characters that share the basic element
目 'eye':
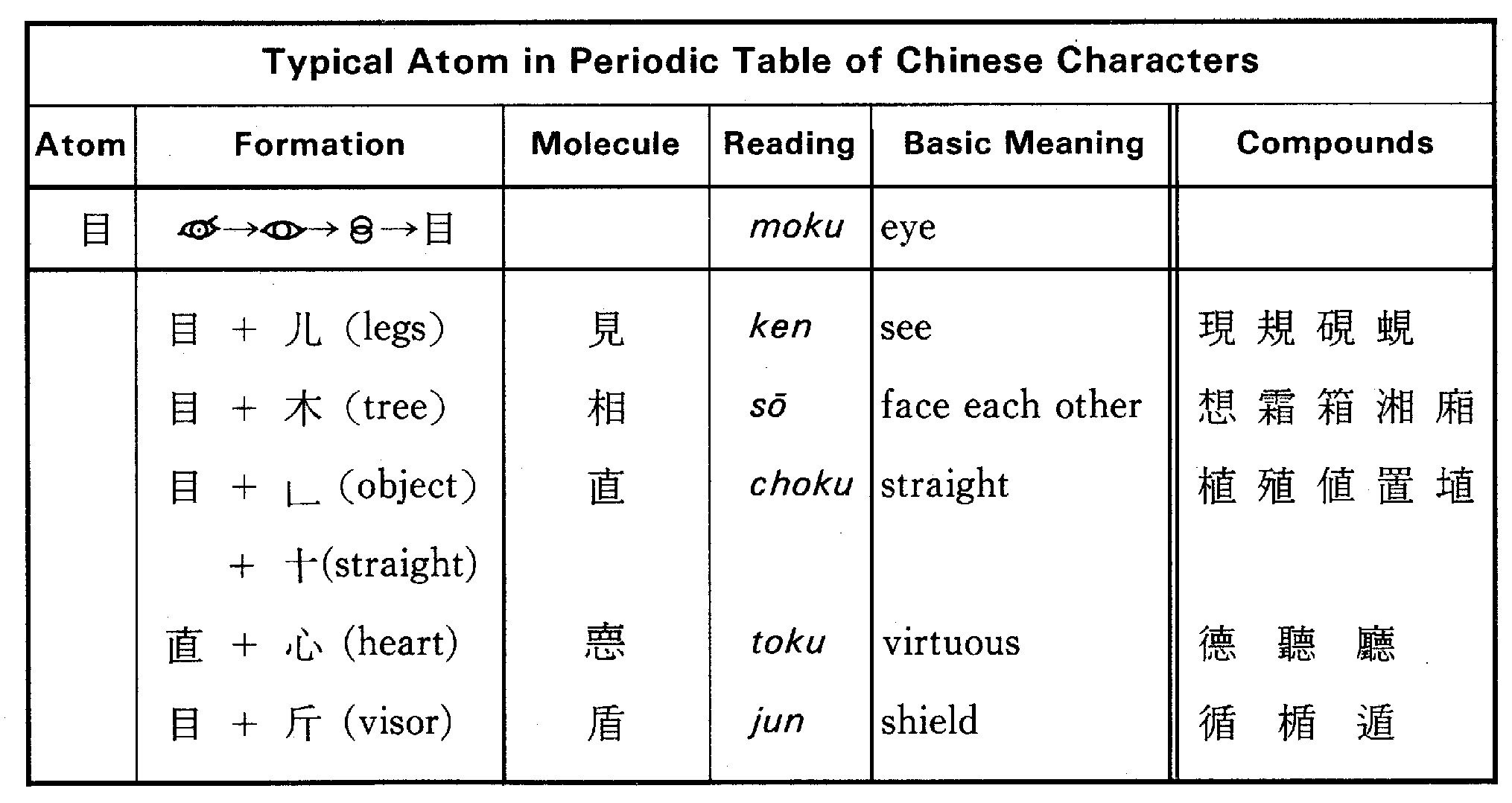 |
Groups of characters sharing the same "molecule" element are closely interrelated 2. They share three important features: (1) they share a basic element of the same shape, (2) they have more or less the same reading, and (3) they share a meaning on the character formation level. Chinese characters thus consist of logically interrelated parts that form a systematic body of symbols to express meaning and sound
In addition to the six traditional categories, there is a seventh one limited to a small number of characters coined in Japan. When the Japanese could not find an appropriate character to represent a particular word, they sometimes created new characters, called 国字 kokuji 'national characters', on the model of the Chinese ones. Most of these have only kun readings (Japanese-derived pronunciations); some, such as 働 dō 'work', have both on (Chinese-derived pronunciations) and kun readings, while others, such as 腺 sen 'gland', have only on readings. In rare instances, as in the case of 腺, a character created in Japan was "exported" back to Chinese.
Footnotes
In the early centuries of the Christian era, the Japanese did not have a writing system of their own. As the Japanese began to interact with the Chinese, they adopted Chinese institutions and adapted them to their own needs. Chinese characters were introduced to Japan via the Korean peninsula in the fourth century A.D. In the next two centuries, Chinese books on philosophy and Buddhism were brought to Japan and studied by the Japanese aristocracy
Initially, the Japanese used the characters for writing in authentic Chinese or a hybrid Japanese-Chinese style. A good example of the latter is the 古事記 kojiki (Ancient Chronicles) written in 712. Since the Japanese did not have their own script, they soon began to use the characters to write the Japanese language as well. In the early stages, they employed the characters purely for their phonetic values. For example, the native Japanese word yama 'mountain' was written 也麻, with the first character representing ya and the second ma. This method of writing is referred to as 万葉仮名 man'yōgana because it was used extensively in the 万葉集 man'yōshū, an eighth-century anthology of Japanese poems.
Because of the markedly different linguistic structures of Chinese and Japanese, the Chinese characters were not well-suited for writing Japanese. Whereas classical Chinese is basically a monosyllabic language with no inflected words, Japanese is a polysyllabic language with various elements attached to the stems of words to express grammatical meanings.
These circumstances led to an extremely interesting method of writing Japanese: the Chinese characters were used for their meanings. The characters were used to write words of Chinese origin, or to write native Japanese words with Chinese characters representing the same or similar meanings. The grammatical elements continued to be written phonetically, but eventually the characters used for their phonetic values were simplified, giving rise to two sets of syllabic scripts, hiragana and katakana, in which each character represents a syllable. For example, the character 安 an 'peaceful' gave rise to the hiragana character あ a, whereas 阿 a was simplified to the katakana character ア a (see Appendix4).
Characters used to represent meaning were pronounced in two ways: (1) the 音読み 'onyomi or 'phonetic reading' and (2) the 訓読みkunyomi or 'explanatory reading'. This phonetic duality of the Chinese characters is fundamental to the nature of the Japanese script. Let us briefly examine how it arose.
In the first method, which is often called the "Sino-Japanese reading" or "Chinese-derived pronunciation,"the characters represent Chinese-derive words or word elements. This method of reading the characters will be referred to as the on reading.The reading assigned to each character was a rough approximation of the original Chines pronunciation. For example, the character 山 'mountain ' was assigned the reading san based on its old Chinese pronunciation (modern Chinese is shān).On readings are found more frequently in compound words (e.g. 連山 renzan 'mountain range') than in independent words (e.g. 天 ten 'heaven').
Since the Japanese often had native words to express the meanings represented by Chinese characters, they began to associate the characters not only with Chinese words but also with purely Japanese words. 山 'mountain', for example, was used to represent the native Japanese word yama 'mountain' with no regard to its Chinese-derived reading san. This method of reading the characters will be referred to as the kun reading.
Originally, the kun reading was a kind of explanation assigned to a character that was used to interpret its meaning in a Chinese text. In other words, it was a native Japanese word that was essentially a translation of the concept represented by the Chinese character. Over the years, certain words became so well established as the translation for a given character that they were considered to be the standard reading or readings for that character. In this manner, 山 acquired the reading yama, which eventually became established as its standard accepted pronunciation along with its on reading san.
A distinctive feature of Chinese characters as used in Japanese is their multiple readings. Since the characters entered Japan over different historical periods and originated from different geographical regions, many characters have acquired several on and/or kun readings. In extreme cases, a character may have more than 100 readings (生 has over 200).
On and kun readings may be combined in four possible ways: on-on, kun-kun, on-kun, and kun-on. Unfortunately, there is no reliable rule for determining if a character is to be read in the on or kun, or for deciding which of several possible readings to select in a particular instance. A rough guideline is that on-on or kun-kun readings are used in compounds, and kun readings in independent words, but there are many exceptions. For example, 毎朝 maiasa 'every morning' is an on-kun compound, though 毎 has the kun reading goto and 朝 the on reading chō
Traditionally, on readings are classified into four types:
During the compilation of this dictionary, several types of on readings that cannot be classified under the traditional categories were found. (The terms used to describe these categories were coined by the editor.)
In addition to the standard on and kun readings, there are a few special ways in which characters can be used. The most important of these are:
Shortly after World War II, the Japanese government implemented language reforms aimed at limiting the number of characters and simplifying their forms, among other things. At the same time, kana orthography underwent extensive reforms to reflect actual pronunciation. For example, the sound kyū was historically written by such combinations as きう and きふ, but is now written きゅう. Large-scale language reforms also took place in China to limit the number of characters and drastically simplify their forms. As a result, many modern Chinese forms are totally different from their corresponding traditional and modern Japanese forms. For example, the traditional form of 發 hatsu 'start; emit' was simplified to 発 in Japanese but to something else in Chinese.
We will not dwell on China, but briefly examine the language reforms that tookplace in Japan. In 1946, a list of characters known as 当用漢字 Tōyō kanji was published, in which the number of characters was limited to 1850. Various amendments and additions followed in the ensuing years. In 1948, for example,an appendix listing 881 characters to be learned in the first six years of compulsory schooling was published, and the number of readings of many characters was reduced. In 1949, the forms of many characters were greatly simplified, while in 1951 a supplementary list of 92 characters was approved for use in personal names,bringing the total to 1942.
In spite of these changes, there was much dissatisfaction among the public, who wanted the number of characters increased. In 1973, 28 more characters for general use were added, while in 1976, 28 name characters were added, followed by an additional 54 in 1981 and 118 in 1990. Meanwhile, cultural organizations and the public at large pressed for greater freedom in the use of Chinese characters in general, as a result of which an expanded list of 1945 characters known as 常用漢字 Jōyō kanji was published in 1981. This brought the total number of characters that can be used in names to 2229.
The general trend to increase the number of characters took place in the schools as well. In 1977, the number of characters to be learned during the six years of compulsory schooling was increased to 996, and in 1989 this number was again increased to 1006 in line with the Ministry of Education's policy to place greater emphasis on reading and writing. Currently (early 1990), the most important official lists approved by the Japanese government as part of the postwar language reforms are:
| Grade | 1977 List | 1989 List |
|---|---|---|
| First | 76 | 80 |
| Second | 145 | 160 |
| Third | 195 | 200 |
| Fourth | 195 | 200 |
| Fifth | 195 | 185 |
| Sixth | 190 | 181 |
| Total | 996 | 1006 |
The principal change introduced in the new list was the moving of 60 characters
from higher to lower grades. For example, fourteen third-grade characters have
become second-grade characters. In addition, twenty new characters were added
to the list, while ten characters were deleted, as shown below:
| Additions(20) | 皿 昔 笛 豆 箱 札 松 巣 束 梅 桜 枝 飼 夢 激 盛 装 誕 並 暮 |
| Deletions(10) | 歓 称 壱 勧 兼 釈 需 是 俗 弐 |
See Appendix 10 Jōyō Kanji List for a full listing of the Education Kanji .
3. Jinmei Kanji The 人名用漢字 Jinmeiyō kanji, or "Name Characters," is an official list (published in 1981) of 166 characters approved for use in personal names in addition to the Jōyō Kanji list. In April 1990, 118 name characters were added, bringing the total to 284. (There was not enough time to incorporate these changes into the present edition.)
The promulgation of the Jōyō/Tōyō Kanji lists as part of the postwar reforms made it necessary to adopt various measures to ensure their smooth implementation. One problem was that it became impossible to write certain common words that included characters not in the official list. To solve this problem, the government published a list of simpler characters and words, called 同音の漢字による書きかえ dōon no kanji ni yoru kakikae, that may be used to replace the characters not in the list. These characters, which we will call phonetic replacement characters, have the same sound, and, often, the same (or a similar) meaning as the characters being replaced. The latter will be called phonetically replaced characters.
For example, the character 繋 (phonetically replaced character) in 連繋 renkei
'connection, linking, contact' was replaced by 係 (phonetic replacement character),
which has the same on reading and is similar to it in meaning,
so that the word is now written 連係. In addition to the 170 phonetic replacement
characters appearing in the aforementioned list, there are many others which
are in common use but do not appear in the list. For example, 混 replaces 渾 in
the word 渾沌 konton 'chaos'.
The Japanese writing system is composed of two syllabic scripts, called 平仮名 hiragana and 片仮名 katakana, and thousands of Chinese characters, called 漢字 kanji. The three scripts basically have different functions. Hiragana is used mostly to write grammatical elements, such as inflectional verb endings, and sometimes for writing native Japanese words. For example, in 見た mita the kanji 見 represents the stem of the verb 見る miru 'see' and た ta is a verb ending for forming the past tense. The kana endings attached to a kanji base or stem are called 送り仮名 okurigana. Katakana is used mostly to write Western loanwords, such as プリンター purintaa; 'printer', and onomatopoeic words, such as カチッと kachitto 'with a click'.
Kanji are used to write the core of the Japanese vocabulary. This includes words, especially nouns, of Chinese origin and words coined in Japan on the Chinese model, such as 山脈 sanmyaku 'mountain range', as well as native Japanese words, such as 山 yama 'mountain'. Kanji have three basic properties: form, sound, and meaning. Each character may be pronounced according to its Chinese derived on reading, or one of several native Japanese kun readings, and each reading may have numerous meanings associated with it.
A running Japanese text consists of a mixture of kanji and kana, with the latter normally outnumbering the former. For example:
漢字を組み合わせることによって多数の熟語が作り出せます。
Kanji o kumiawaseru koto ni yotte tasū no jukugo ga tsukuridasemasu.
Numerous compound words can be formed by combining Chinese characters.
In the above sentence, particles such as を o (object marker), as well as verb endings (-わせる -waseru in 組み合わせる kumiawaseru 'combine'), are written in hiragana, whereas nouns, such as 熟語 jukugo 'compound word', are written in kanji. Hiragana characters serve as natural borderlines that help the reader segment the text into meaningful units. For this reason, a Japanese text is easier to read than a running Chinese text, which consists of Chinese characters only.
One of the most important characteristics of Chinese characters is their ability to convey meaning. Just how they do this is the subject of a vast literature full of conflicting theories. Chinese characters have been described by such terms as logographic (symbols for words), ideographic (symbols for ideas), and morphographic (symbols for morphemes). Scholars disagree over the precise terminology and function of the characters.
According to one extreme view, the characters convey meaning phonetically and their ideographic nature is nothing but a myth. According to another view, the characters can convey meaning directly; that is, with little or no dependence on their pronunciations. Alphabetic symbols, on the other hand, are one step removed from that which is ultimately represented because they normally stand for the sounds of speech, which are in turn associated with meaning. Various other theories take intermediate positions between these two extremes. The whole question is highly controversial, but it is generally accepted that, whatever linguistic units the characters actually correspond to, their essential nature is to convey both meaning and sound, not just sound.
Another important characteristic of Chinese characters is their high productivity. By combining a stock of a few thousand characters, countless compound words are generated. 戦 sen 'war', for example, is combined with other characters to form numerous compound words related to war, such as 戦友 sen'yū 'comrade-in-arms' and many others. Chinese characters in Japanese function much the same way as Latin and Greek roots do in English. Each character has one or more distinct meanings, and often functions as a highly productive word-building element.
| hydrophobia Greek | 恐水病 | kyōsuibyō | fear-water-illness |
| aquarium Latin | 水族館 | suizokukan | water-family-building |
| waterwheel Anglo-Saxon | 水車 | mizuguruma | water-wheel |
In English, the relationship between the above words is somewhat obscured by
the fact that the concept of water is expressed in three different written forms,
i.e., hydr, aqua, and water. In Japanese, on the other hand, although
水 has different phonetic forms, i.e., an on reading of sui and a kun
reading of mizu, it has only one A further characteristic of Chinese characters is their semantic transparency.
As each component of a compound word conveys a distinct meaning, the meaning
of the resulting word is often self-evident. For example, 好奇心 "like + strangeness
+ heart (mind)" means 'curiosity', 貧血症 "little + blood + illness" means 'anemia',
and 閉所恐怖症 "closed + place + fear + illness" means 'claustrophobia'. Once
the meanings of the components are known, relatively little effort is needed
to learn these words.
Finally, Japanese has a large number of homophones (words that sound
the same but are written differently). Kōki and kikō,
for instance, represent about a dozen words in common use, and there are many
more less frequent ones. Since each character has a distinct form (and meaning),
kanji serve to distinguish such words from each other. Thus, 機構 kikō
'mechanism' is easily distinguished from 帰港 kikō 'returning to
the harbor'.
In summary, the principal features of the Japanese script are:
Languages differ in the processes by which they form new words. The Japanese
language is agglutinative; that is, it forms words by putting together
basic elements, called morphemes, that retain their original forms and
meanings with little change during the combination process. A morpheme is a
distinctive linguistic unit of relatively stable meaning that cannot be divided
into smaller meaningful parts. As a rule, each Chinese character represents
one morpheme.
Compounding and derivation are among the most important word-formation
processes in Japanese. Compounding consists of combining two or more words or
word elements having their own lexical meaning (having a substantial meaning
of their own) to produce a new unit that functions as a single word. Since the
Chinese characters are extremely productive in their ability to generate new
words, compounding plays a major role in Japanese word-formation. By combining
a stock of a few thousand characters, hundreds of thousands of compound words
are created.
Traditionally, a compound word is considered to be a combination of two or
more free words, such as headwaiter, which consists of head and
waiter. In Japanese, a compound may be any combination of free words,
combining forms, and affixes that together function as a single word. The resulting
compound is distinct from, but related to, its constituent components. For example,
the compound 造船所 zōsenjo 'shipyard' consists of the free word
造船 'shipbuilding' (造 'make; build' + 船 'ship') followed by the suffix 所 'place'.
Derivation refers to creating a new word by adding to a stem a word element
such as a suffix that expresses grammatical meaning but has no lexical meaning.
For example, the noun 黒 kuro 'black' is combined with the adjective-forming
suffix い i to form the adjective 黒い kuroi 'black'.
Derivation should not be confused with inflection, which consists of
adding word endings or modifying the form of a word in order to indicate various
grammatical functions, such as tense. The resulting word is another form of
the original word, not a new word in itself. For example, the last syllable
of the verb 帰る kaeru 'to return' is inflected to yield 帰れ kaere,
the imperative form. Inflectional word endings in Japanese are usually written
in hiragana.
The precise distinctions between compounding, derivation, and inflection involve
complex theoretical problems that need not concern the nonspecialist.
As we have seen above, kanji may be read in one of two ways: the on
reading and the kun reading. For each reading, a character may
function as an independent word (any free word that can be used on its own)
or as a word element (bound form used only in combinations). Since a character
may have a different sense associated with each reading and each function, the
meaning of a character can be said to operate on four distinct but related levels:
Each character may have numerous meanings on one or more of the four levels,
and the levels may interact in a complex way. On each level, the characters
may be combined in various ways, such as bound + free, bound + bound, free +
free, etc., and may have several, sometimes a dozen or more, different meanings.
Each character may have several on and kun readings,
and each reading may have several derived words associated with it, which in
turn have many meanings; or the character may function as a word element with
one or more meanings.
In some cases, on each level the meanings are totally different; in others,
they may be similar but not quite the same. Often there is partial overlapping
of some meanings but total inequality of others. For example, the on
word element 山 san and the independent kun word
as well as kun word element 山 yama share the meaning
'mountain', but the on word element san also means
'Buddhist temple', as in 本山 honzan 'head temple', a meaning which
is not shared by yama.
Generally, the more common a character is, the more numerous are its meanings
and the more complex is the relationship between them. An extreme example is
上 jō 'up; go up'. This dictionary lists a total of 114 meanings
for 上, subdivided into 16 subentries. It has 27 meanings as an on word element,
3 meanings as an independent on word, 17 meanings for 5 kun
word elements and 67 meanings for 9 independent kun words. Although
上 is a very long entry and is hardly typical, many characters do have more than
ten on and kun meanings combined.
The Japanese script is now in a state of flux, and is being constantly adapted
to the needs of the times. In this brief outline we have only touched upon its
most important aspects, especially the role of Chinese characters, to the extent
deemed necessary for using this dictionary effectively.
3.3 Word-Formation
3.4 Meaning of Kanji